🔢 Neural network to recognize handwritten digits from scratch!
# Install the required libraries for python. Start the cell by pressing Shift + Enter.# In order to practice in listener mode (without doing any exercises or# without modifying anything) simply run the cells one after another,# by pressing Shift + Enter!pip install numpy --quiet!pip install tensorflow --quiet!pip install pandas --quiet!pip install keras --quiet
[notice] A new release of pip is available: 23.2.1 -> 23.3
[notice] To update, run: python3.9 -m pip install --upgrade pip
[notice] A new release of pip is available: 23.2.1 -> 23.3
[notice] To update, run: python3.9 -m pip install --upgrade pip
[notice] A new release of pip is available: 23.2.1 -> 23.3
[notice] To update, run: python3.9 -m pip install --upgrade pip
[notice] A new release of pip is available: 23.2.1 -> 23.3
[notice] To update, run: python3.9 -m pip install --upgrade pip
We need to recognize handwritten digits from their images. Since there are 10 digits, there are 10 classes in our classification task.
Our MNIST dataset is often used to demonstrate the capabilities of various machine learning and deep learning algorithms, as it is quite easy to achieve good performance accuracy.
✍️ Data Analysis Process:
Load the data for training and testing
Pre-process the data
Create a model for training
train the model
Test the model
Try to improve the model
Let’s load the necessary libraries: keras for working with neural networks, numpy for scientific computing, matplotlib for plotting.
Our neural network will do a series of successive transformations of the data, so we need the Sequential neural network type
The types of transformations we will be working with are: dense layer Dense, Activation Activation, matrix to long vector Flatten.
We’ll also be using MNIST data - it can be downloaded from public sources using keras.
Perform the cell below:
from tensorflow import kerasfrom keras.models import Sequentialfrom keras.layers import Dense, Activation, Flattenimport keras.datasetsimport numpy as npfrom matplotlib import pyplot as plt
📦 1. Data Loading.
keras already has several popular datasets that can be easily loaded. Let’s load the MNIST dataset.
print(f"🤖 Total {X_train.shape[0]} images in the training sample and {X_test.shape[0]} in the test sample.")print(f"🤖 This is what the first element of our training sample looks like. It's a matrix of size {X_train[0].shape}")print(X_train[0])
Normalize values on [0,1] and put the target variable into one-hot format
Data normalization often contributes to more stable training of ML models. Here we will make sure that the values of all input features lie between 0 and 1. We do this by dividing by 255 (because, as you can see above, they are now integers between 0 and 255).
The neural network also needs the value of the output variable in one-hot format. This is done by the function from keras keras.utils.to_categorical, which takes as input the initial vector of output variable values and the number of classes.
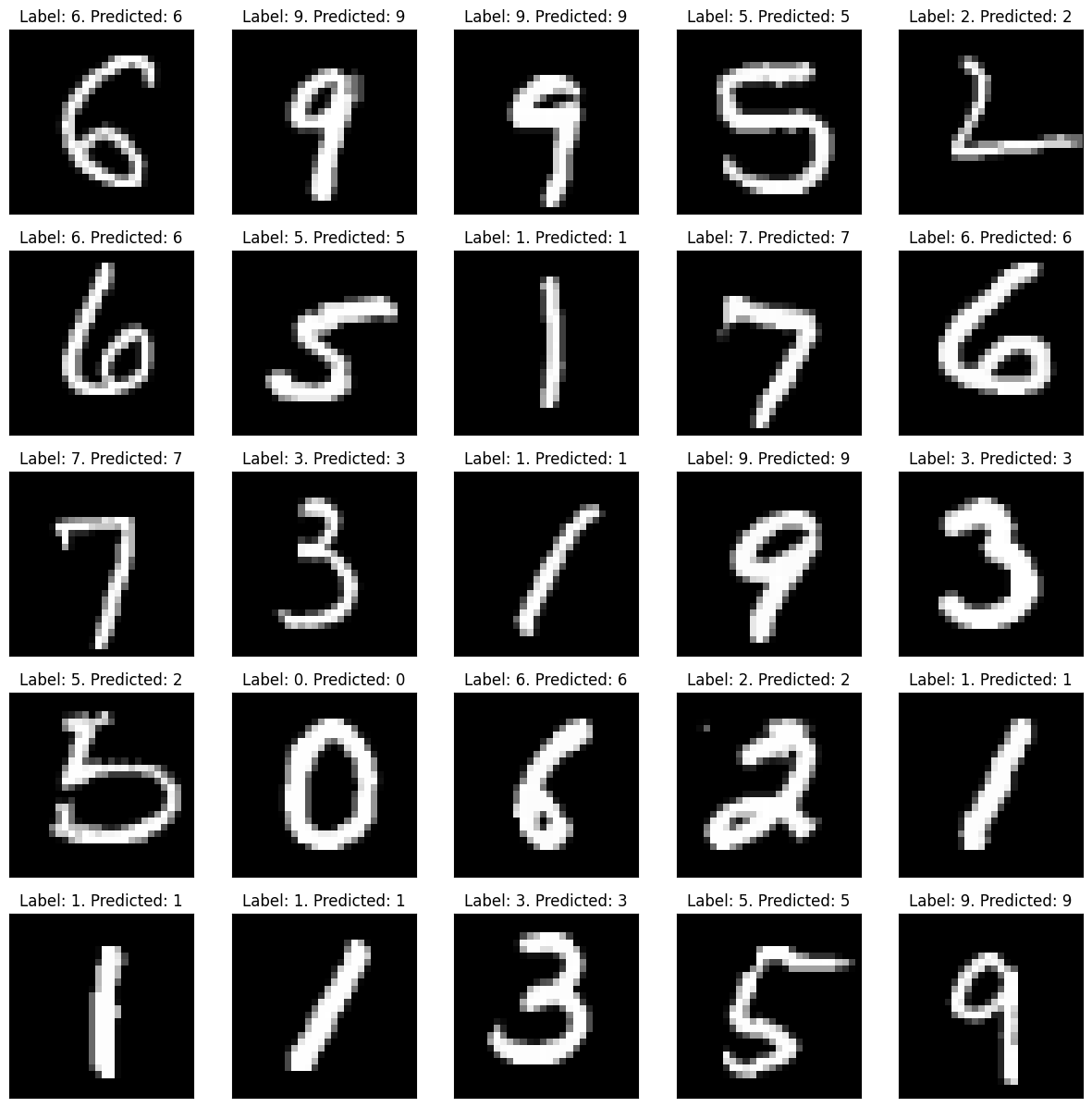
# Auxiliary functions for images.def show_img(img, ax=None, title=None):"""Shows a single image."""if ax isNone: ax = plt.gca() ax.imshow(img, cmap='gray') ax.set_xticks([]) ax.set_yticks([])if title: ax.set_title(title)def show_img_grid(imgs, titles):"""Shows a grid of images.""""" n =int(np.ceil(len(imgs)**.5)) _, axs = plt.subplots(n, n, figsize=(3* n, 3* n))for i, (img, title) inenumerate(zip(imgs, titles)): show_img(img, axs[i // n][i % n], title)def show_examples(data, label, predicted =None): idxs = np.random.randint(0, len(data), 25)if np.array(label).max() <=1: label = np.argmax(label, axis=-1)if predicted isnotNone:if np.array(predicted).max() <=1: predicted = np.argmax(predicted, axis=-1) show_img_grid( [data[idx] for idx in idxs], [f'Label: {label[idx]}'if predicted isNoneelsef'Label: {label[idx]}. Predicted: {predicted[idx]}'for idx in idxs], )show_examples(X_test, y_test)
Let’s look at the form in which we store the input features by printing the size of the first object from the training sample.
For the MNIST data, these are 28 by 28 images.
input_size = X_train[0].shapeprint(f"🤖 Image size {input_size} pixels")print(f"🤖 The values of all pixels are between {X_train.min()} and {X_train.max()}")print(f"🤖 Class label of the first picture in the original format {np.argmax(y_train[0])}")print(f"🤖 Class label of the first picture in one-hot format {y_train[0]}")
🤖 Image size (28, 28) pixels
🤖 The values of all pixels are between 0.0 and 1.0
🤖 Class label of the first picture in the original format 5
🤖 Class label of the first picture in one-hot format [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
💃 3. Creating a model for training
Sequential here means sequential type of model where we add layers one after another.
**Add layer after layer to the model.
First we pull the picture into a long vector with the Flatten layer. ** Then we add a fully connected layer - the neurons in the next layer depend on all the variables in the previous layer. ** Next we apply a nonlinear ReLU transform **
Then comes the next full-link layer. It has 10 outputs - the number of classes.
At the end we use the softmax activation function (it turns any vector of 10 numbers into a probability vector, i.e. all components are non-negative and their sum is 1).
model = Sequential()model.add(Flatten())model.add(Dense(units=16))model.add(Activation('relu'))model.add(Dense(units=10))model.add(Activation('softmax'))
After describing the architecture, the model should be compiled by specifying the loss function to be minimized, optimizer and asking the model to output the accuracy of operation on a test pattern during the training process
Training with data, number of epochs and subsample size
Now the structure of the model and how we are going to train it is set. We do this in a similar way to sklearn - using the fit method.
After running fit, we optimize the parameters by gradient descent. At each step of the gradient descent, we use a loss function that is computed over only a portion of the full sample.
Two additional parameters for training are: * batch_size - the size of the subsample that is used for one optimization step * epochs - the number of epochs - how many times we go through the full sample
print(f"🤖 Number of trainable parameters in the model {trainable_params}")print(f"🤖 Prediction accuracy on the test sample {test_accuracy:.3f}")print(f"🤖 Loss function value on test sample {test_loss:.3f}")
🤖 Number of trainable parameters in the model 12730
🤖 Prediction accuracy on the test sample 0.935
🤖 Loss function value on test sample 0.231
show_examples(X_test, y_test, model(X_test))
💎 EXERCISE
Try to change any parameters below so that the quality of predictions on the test sample becomes at least 97%. The one who does this with the fewest number of model parameters wins.
# Try changing the parameters below to your likingNUMBER_NEURONS_IN_THE_FIRST_LAYER =16ACTIVATION_FUNCTION ="relu"# "selu", "elu", "softmax", "sigmoid", "relu", ...OPTIMIZER ="adam"# "adam", "nadam", "rmsprop", "sgd",...NUMBER_EPOCHES =5BATCH_SIZE =128model = Sequential()model.add(Flatten())model.add(Dense(units=NUMBER_NEURONS_IN_THE_FIRST_LAYER, activation=ACTIVATION_FUNCTION))model.add(Dense(units=10, activation="softmax"))model.compile(loss='categorical_crossentropy', optimizer=OPTIMIZER, metrics=['accuracy'])model.fit(X_train, y_train, epochs=NUMBER_EPOCHES, batch_size=BATCH_SIZE)test_loss, test_accuracy = model.evaluate(X_test, y_test)trainable_params =int(sum([keras.backend.count_params(w) for w in model.trainable_weights]))print(f"🤖 Number of trainable parameters in model {trainable_params}")print(f"🤖 Prediction accuracy on the test sample {test_accuracy:.3f}")print(f"🤖 Loss function value on test sample {test_loss:.3f}")
Epoch 1/5
469/469 [==============================] - 0s 774us/step - loss: 0.6255 - accuracy: 0.8248
Epoch 2/5
469/469 [==============================] - 0s 853us/step - loss: 0.2942 - accuracy: 0.9172
Epoch 3/5
469/469 [==============================] - 0s 854us/step - loss: 0.2510 - accuracy: 0.9285
Epoch 4/5
469/469 [==============================] - 0s 894us/step - loss: 0.2273 - accuracy: 0.9346
Epoch 5/5
469/469 [==============================] - 0s 854us/step - loss: 0.2117 - accuracy: 0.9391
313/313 [==============================] - 0s 511us/step - loss: 0.2113 - accuracy: 0.9389
🤖 Number of trainable parameters in model 12730
🤖 Prediction accuracy on the test sample 0.939
🤖 Loss function value on test sample 0.211
📈 EXTRA: Improve the model (try to add a convolution layer)
Let’s add explicitly the number of channels to our dataset - this is important for convolution layers. I.e. the transformation (60000, 28, 28, 28) -> (60000, 28, 28, 28, 1) is done. This does not change anything in the data.
X_train, X_test = X_train.reshape((60000, 28, 28, 1)), X_test.reshape((10000, 28, 28, 1))input_size = X_train[0].shapeprint(f"🤖 Now the size of the first image is {input_size}")print(f"🤖 Width {input_size[0]}, Length {input_size[1]}, Number of channels (colors) {input_size[2]}")
🤖 Now the size of the first image is (28, 28, 1)
🤖 Width 28, Length 28, Number of channels (colors) 1
We use a new type of transformation in the layer - convolutional Conv2D
from keras.layers import Conv2D, MaxPooling2D
Model Creation. Sequential here means a sequential type of model, where we add layers one after another
Here we use a convolutional layer that trains 32 3x3 filters to find specific geometric (customizable during training) patterns in the input image.
After describing the architecture, the model should be compiled by specifying the loss function to be minimized, optimizer and asking the model to output the accuracy of operation on a test pattern during the training process
Let’s check the quality of the model on the test data. The loss and accuracy are derived.
test_loss, test_accuracy = conv_model.evaluate(X_test, y_test)trainable_params =int(sum([keras.backend.count_params(w) for w in conv_model.trainable_weights]))
print(f"🤖 Number of trainable parameters in the model {trainable_params}")print(f"🤖 Prediction accuracy on the test sample {test_accuracy:.3f}")print(f"🤖 Loss function value on test sample {test_loss:.3f}")
NameError: name 'trainable_params' is not defined
🤕 EXTRA: Collapsed layers, dropout
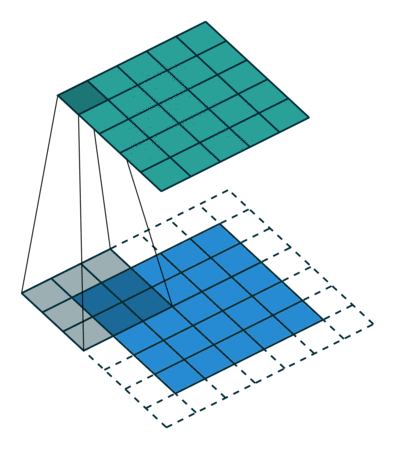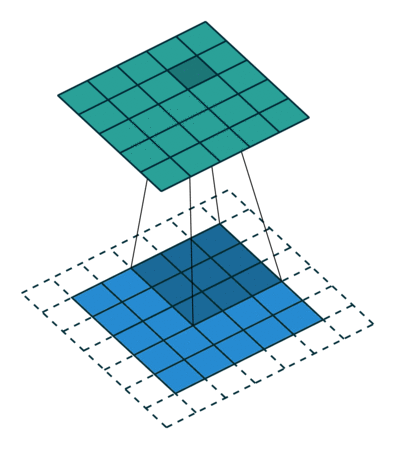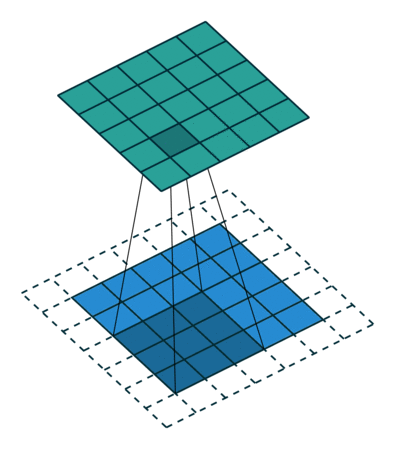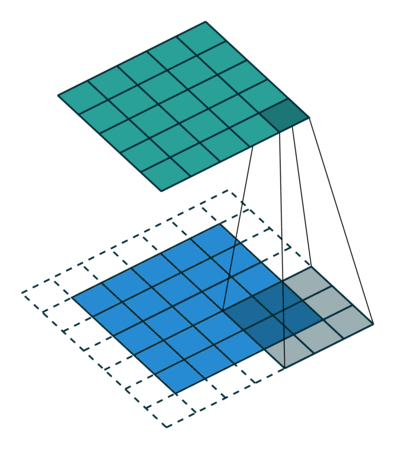
Several filters of small sizes are generated and trained to recognize some characteristic combinations of pixels (patterns). The image below is 5x5 pixels, the filter has dimensions 3x3. At the output of such an operation we have a picture of the same size, in each of the pixels of which is written the result of convolution (number) of this filter with the picture when the center of the filter in this pixel. For this purpose, the original picture must be complemented at the edges. Usually it is done either by zeros or by duplicating the nearest pixels (padding).
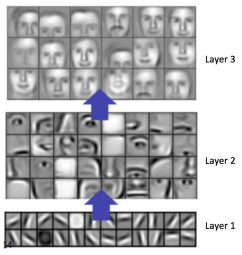
The deeper the convolution layer is, the more complex patterns it is able to recognize:
Dropout - a technique to save neural networks from overtraining, whereby some neurons are accidentally “switched off” from patterns during training.
Alternatively, instead of training one large network, several smaller sub-networks are trained simultaneously, and the results are then averaged (in a sense, smoothed).
Let’s try to see how to write a network consisting of several convolutional layers on keras.
from keras.layers import Conv2D, MaxPooling2D, Dropout# Try changing the parameters below to your likingNUMBER_OF_FILTERS_IN_FIRST_LAYER =32NUMBER_OF_FILTERS_IN_THE_SECOND_LAYER =64DROPOUT_PROBABILITY_OF_DROPOUT =0.1ACTIVATION_FUNCTION ="relu"# "selu", "elu", "softmax", "sigmoid", "relu", ...OPTIMIZER ="adam"# "adam", "nadam", "rmsprop", "sgd",...NUMBER_EPOCHES =5BATCH_SIZE =128model = Sequential()model.add(Conv2D(NUMBER_OF_FILTERS_IN_FIRST_LAYER, (3, 3), activation=ACTIVATION_FUNCTION))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(DROPOUT_PROBABILITY_OF_DROPOUT))model.add(Conv2D(NUMBER_OF_FILTERS_IN_THE_SECOND_LAYER, (3, 3), activation=ACTIVATION_FUNCTION))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(DROPOUT_PROBABILITY_OF_DROPOUT))model.add(Flatten())model.add(Dense(units=10, activation="softmax"))model.compile(loss='categorical_crossentropy', optimizer=OPTIMIZER, metrics=['accuracy'])history = model.fit(X_train, y_train, epochs=NUMBER_EPOCHES, batch_size=BATCH_SIZE)test_loss, test_accuracy = model.evaluate(X_test, y_test)trainable_params =int(sum([keras.backend.count_params(w) for w in model.trainable_weights]))print(f"🤖 Number of trainable parameters in model {trainable_params}")print(f"🤖 Prediction accuracy on the test sample {test_accuracy:.3f}")print(f"🤖 Loss function value on test sample {test_loss:.3f}")
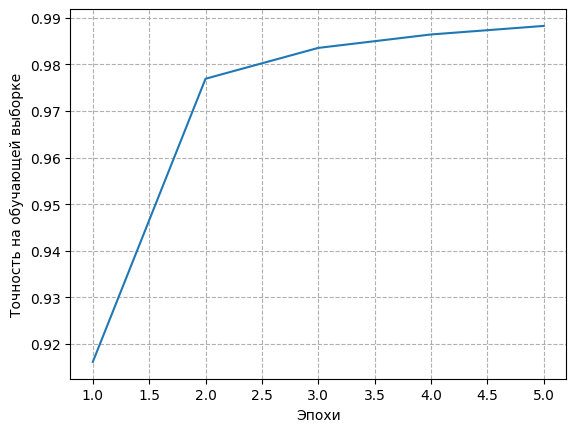
plt.plot(list(range(1, ЧИСЛО_ЭПОХ+1)), history.history['accuracy'])plt.xlabel("Эпохи")plt.ylabel("Точность на обучающей выборке")plt.grid(linestyle="--")plt.show()